My first code created by Gemini
I have been slowly starting to use AI on my Mac Studio. Since I am embedded in the Google ecosystem, my AI of choice is Gemini.
I spent most of last weekend taking a Zoom course called C135 Generative AI Mastermind INTL. It opened my eyes to see what could be done using AI. Their bottom line was that it is vital to create a structured requirements document to get good results. This week I decided to try and do something difficult. I tried this using Bolt (recommended in the course, but ran out of tokens, so I tried it using Gemini (I had a Pro subscription).
For over a decade I have been videoing the concerts presented by the Oak Ridge Civic Music Association (ORCMA), and placing them in our YouTube channel https://youtube.com/orcma.
If you click on the Videos, you will see all of the videos I have posted since 2013. Unfortunately, when I began doing this, I had no idea how large this collection would become, and I had no set format for creating the description of the video. New videos created since I have been using DaVinci Resolve Studio have tags that are uploaded to YouTube and which create an easy-to-parse description:
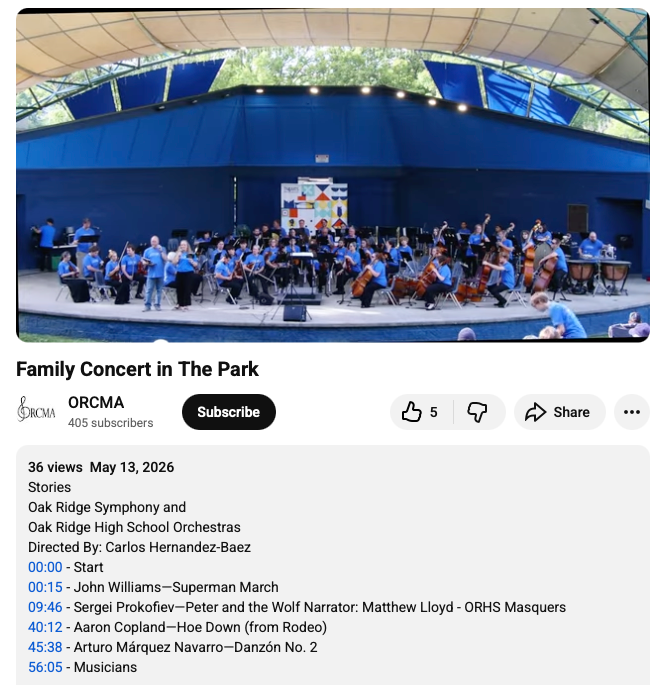
Old videos presented the information a gazillion different ways, making it very difficult to parse; sometimes the metadata were missing altogether.
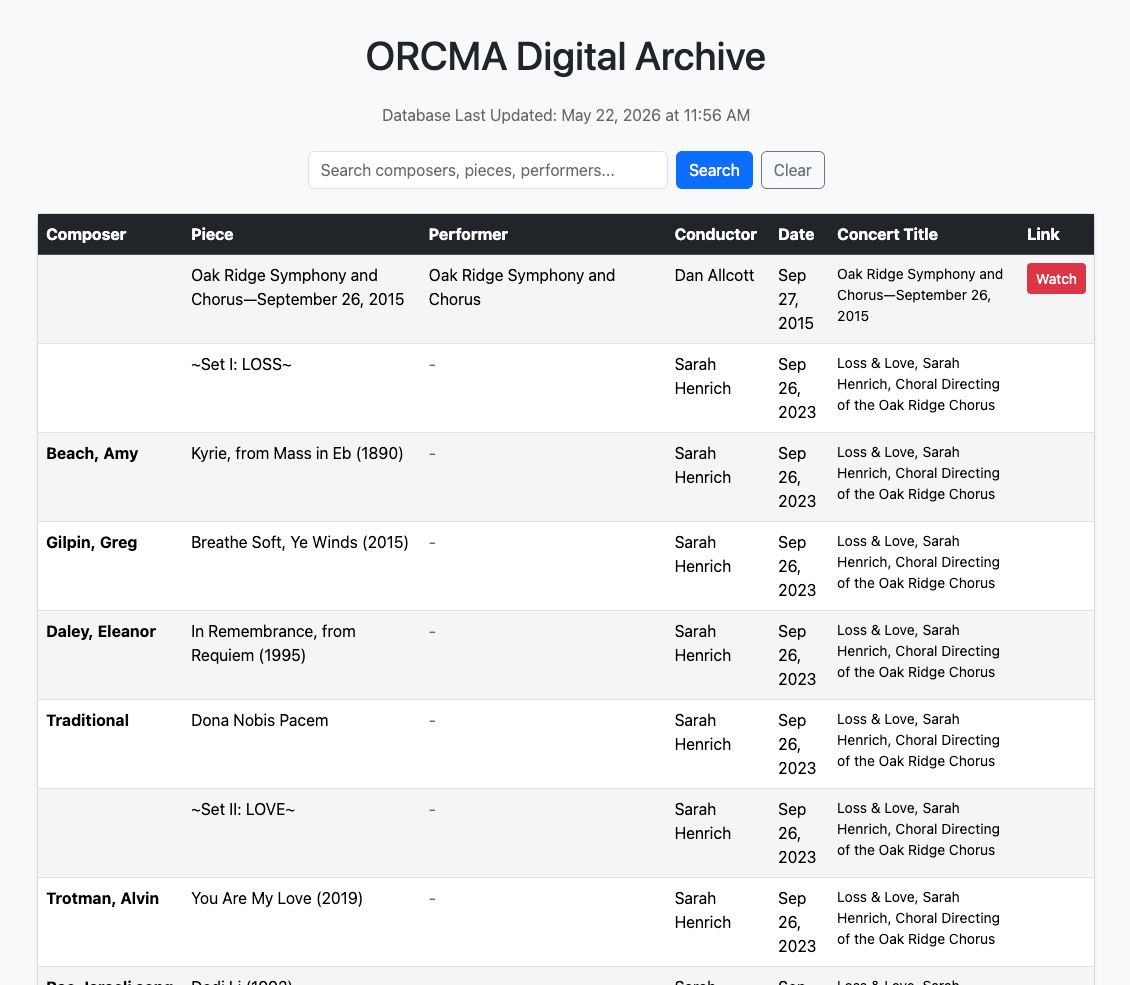
So armed with a Gemini Pro subscription, and the knowledge that could do a lot I decided to make a searchable Web page that would list all performances that I have videoed. I note that not all videos are Public because of things such as copyright or contractual limitations. However, I wanted to list the contents of these concerts so that people (e.g., our Music Director) could see what pieces have been performed.
Check out the resulting Web page. It is not perfect, but the information is there, and it is a waste of time solving all edge cases.
Gemini summarized our journey together nicely:
To help you write your blog post, here is the reconstruction of the evolution of this project, starting from your original goal down through the specific architectural instructions we solved together.
The Core Objective
Your original goal was to build an automated, offline pipeline (update_archive.py) capable of scraping the Oak Ridge Civic Music Association (ORCMA) YouTube channel. The ultimate objective was to parse the raw video titles and description text, cleanly extract the classical metadata, and structurally rebuild a clean, searchable SQLite database (orcma_archive.db) to power a video gallery on the website.
The Evolution of Your Technical Instructions
As the project scaled, your requirements grew from a basic web-scraper into a highly customized, resilient extraction engine. Here are the core instruction milestones you established:
1. The Dual-Stage Ingestion Pipeline
-
Public Extraction in Batches: Scrape the main public channel (
@orcma/videos), but fetch it in explicit chunks of 90 videos at a time to prevent long-running connection drops. -
Unlisted Archive Ingestion: Explicitly iterate through a hardcoded array of private/unlisted YouTube URLs so they are preserved in the database even though they don't appear on the public feed.
2. Deep Description Parsing & Classical Metadata Extraction
-
The Classical Split Rule: Look for timestamps (e.g.,
07:36) or known composer prefixes to identify individual tracks within a single long concert video. Split the text using hyphens, dashes, or semicolons to isolate the Piece from the Soloist/Performer. -
The "Last, First" Formatting Constraint: For database uniformity, all composer and artist names must automatically normalize to a traditional indexed format (e.g., transforming Johann Sebastian Bach into
Bach, Johann Sebastian). -
The Movement & Junk Filter: Implement a rule-based regex to explicitly ignore applause, tuning, intermission, or movement markers (like I. Allegro or II. Adagio) so they don't generate duplicate or broken database entries.
3. Bypassing YouTube’s Anti-Bot Defense
-
Humanizing Delays: Enforce a strict anti-scraping policy using an average 10-second sleep interval (
sleep_interval: 5,max_sleep_interval: 15) between video fetches to mimic a human browser and protect your IP from being flagged. -
"Initially, I considered routing traffic through a Tor proxy to rotate IPs. However, YouTube aggressively flags and blocks known Tor exit nodes, making the script hang constantly. Instead, the true solution was building a custom Cookie Rotator...
-
The Infinite Cookie Rotator: Cycle sequentially through multiple Netscape-formatted session files (
cookies_1.txt,cookies_2.txt, etc.). Shift to the next identity automatically every 90 requests using a modulo loop wrap-around, ensuring the script checks for file existence on disk so a missing or deleted cookie file won't cause a crash. -
Fail-Fast Mechanics: Prevent silent infinite retry loops on HTTP or socket errors by enforcing fixed timeouts and limiting retries to 3 attempts.
4. Data Sanitization & Edge-Case Handling
-
The Master Lists: Cross-reference strings against custom Python arrays (
KNOWN_COMPOSERS,KNOWN_CONDUCTORS,KNOWN_ENSEMBLES) to prioritize exact matches before falling back to raw regex guessing. Since Python is not compiled, it is best to put these in thew body of the code rather in external files. -
Festival Context Preservation: If a standalone video has no internal timestamps but the description mentions a festival series (like Rock to Bach), capture that context and explicitly populate it into the
concert_titlefield while remapping the isolated title to thesoloistcolumn. -
Blank-Space Hygiene: Instead of letting the script output literal placeholder strings like
"Unknown"or"Unknown Composer"for uncredited fields, sanitize the outputs down to perfectly clean, empty rows ("").
The "Overnight Run" Breakthrough
A great focal point for your blog is how we solved the illusion of the script getting "stuck." Because the script was intentionally pausing for up to 15 seconds per video to stay under YouTube's radar, processing a batch of 90 videos meant it would sit in complete silence for 15 minutes.
By turning on yt-dlp's heartbeat logging while turning off infinite retries, you transformed a seemingly frozen program into a highly stable, self-rotating automation engine that successfully completed its massive ingestion overnight!
Here is the python code to scrape YouTube with minor changes for security:
import sqlite3 import re import yt_dlp import shutil import os from datetime import datetime KNOWN_COMPOSERS = [ "Ludwig van Beethoven", "Wolfgang Amadeus Mozart", "Johann Sebastian Bach", "Richard Wagner", "Franz Joseph Haydn", "Joseph Haydn", "Johannes Brahms", "Franz Schubert", "Peter Ilyich Tchaikovsky", "George Frideric Handel", "Igor Stravinsky", "Robert Schumann", "Frederic Chopin", "Felix Mendelssohn", "Claude Debussy", "Franz Liszt", "Antonín Dvořák", "Giuseppe Verdi", "Gustav Mahler", "Antonio Vivaldi", "Richard Strauss", "Serge Prokofiev", "Dmitri Shostakovich", "Béla Bartók", "Hector Berlioz", "Anton Bruckner", "Giovanni Pierluigi da Palestrina", "Claudio Monteverdi", "Jean Sibelius", "Maurice Ravel", "Ralph Vaughan Williams", "Modest Mussorgsky", "Giacomo Puccini", "Henry Purcell", "Gioacchino Rossini", "Edward Elgar", "Sergei Rachmaninoff", "Camille Saint-Saëns", "Josquin Des Prez", "Nikolai Rimsky-Korsakov", "Carl Maria von Weber", "Jean-Philippe Rameau", "Jean-Baptiste Lully", "Gabriel Fauré", "Edvard Grieg", "Christoph Willibald Gluck", "Arnold Schoenberg", "Charles Ives", "Paul Hindemith", "Olivier Messiaen", "Aaron Copland", "Francois Couperin", "William Byrd", "Erik Satie", "Benjamin Britten", "Bedrich Smetana", "Bedrick Smetana", "César Franck", "Alexander Nikolayevich Scriabin", "Georges Bizet", "Domenico Scarlatti", "Georg Philipp Telemann", "Anton Webern", "Roland de Lassus", "George Gershwin", "Gaetano Donizetti", "Carl Philipp Emanuel Bach", "Archangelo Corelli", "Thomas Tallis", "Johann Strauss II", "Leos Janácek", "Guillaume de Machaut", "Alban Berg", "Alexander Borodin", "Vincenzo Bellini", "Charles Gounod", "Jules Massenet", "Francis Poulenc", "Giovanni Gabrieli", "Pérotin", "Heinrich Schütz", "John Cage", "Giovanni Battista Pergolesi", "John Dowland", "Gustav Holst", "Dietrich Buxtehude", "Ottorino Respighi", "Guillaume Dufay", "Hugo Wolf", "Carl Nielsen", "William Walton", "Darius Milhaud", "Orlando Gibbons", "Giacomo Meyerbeer", "Samuel Barber", "Tomás Luis de Victoria", "Léonin", "Manuel de Falla", "Hildegard von Bingen", "Mikhail Glinka", "Alexander Glazunov", "Don Carlo Gesualdo", "Astor Piazzolla", "Juan Bautista Plaza", "Luiz Bonfá", "Shostakovich", "W. A. Mozart", "Mozart", "William Grant Still", "Ennio Morricone", "Samuel Coleridge Taylor", "Samuel Coleridge-Taylor" ] KNOWN_CONDUCTORS = [ "Dan Allcott", "Jaclyn Johnson", "Ian Passmore", "Sarah Henrich", "Wilbur Lin", "Kevin Class", "James Fellenbaum", "Régulo Stabilito", "Cornelia Laemmli Orth","Carlos Hernandez-Baez",'Carlos Hernandez-Baez' ] KNOWN_ENSEMBLES = [ "Oak Ridge Symphony Orchestra", "Oak Ridge Symphony and Chorus", "Oak Ridge Symphony Wind Ensemble", "Oak Ridge Symphony", "Oak Ridge Chorus", "Trillium Trio", "Poulenc Trio", "Frisson", "Borealis Wind Quintet", "Tesla Quartet", "Mirai Brass Quintet", "Akropolis Reed Quintet", "Ariel Quartet", "Karen Kartal & Friends", "Los Angeles Guitar Quartet", "Edgar Meyer", "Cuartete Latinoamericana and Jiji", "Trio Matisse", "Cumberland Piano Trio" ] class CookieRotator: def __init__(self, cookies, rotate_every=90): self.cookies = [c for c in cookies if os.path.exists(c)] self.rotate_every = rotate_every self.request_count = 0 self.index = 0 def get_current(self): return self.cookies[self.index] if self.cookies else None def add_requests(self, count): self.request_count += count while self.request_count >= self.rotate_every: self.request_count -= self.rotate_every if self.cookies: self.index = (self.index + 1) % len(self.cookies) print(f"\n[🔄] Rotation threshold met! Switching to: {self.get_current()}\n") def is_movement(clean_text): text = clean_text.strip() if re.search(r'^(movement|variation|var\.?|satz|act|scene|teil)\s+([IVXLCDM]+|\d+)', text, re.IGNORECASE): return True if re.search(r'^[IVXLCDM]+\b\.?\s+', text): return True if re.search(r'^\d+\.?\s+', text): return True if re.search(r'^(allegro|adagio|andante|moderato|presto|largo|menuet|scherzo|finale|rondo|gavotte|bourrée|gigue|overture|aire|aria)\b', text, re.IGNORECASE): return True if not re.search(r'[-–—:]', text) and len(text.split()) < 8: return True return False def parse_classical_title(video_title): # 1. Strip promotional text from the very beginning safe_title = re.sub(r'(?i)^(?:ORCMA|The Oak Ridge Civic Music Association)\s+presents:?\s*', '', video_title).strip() # 2. Convert long strings of dots (......) into a standard hyphen safe_title = re.sub(r'\.{2,}', ' - ', safe_title) # 3. Existing volume/flat/sharp cleanup safe_title = re.sub(r'^.*?(?:Part|Vol\.?)\s*\d+[\.:]?\s*', '', safe_title, flags=re.IGNORECASE) safe_title = re.sub(r'\b([A-G])\s*[-–—]\s*(flat|sharp)\b', r'\1 \2', safe_title, flags=re.IGNORECASE) # --- Master Composer List Check --- for composer in KNOWN_COMPOSERS: if re.search(rf'\b{re.escape(composer)}\b', safe_title, re.IGNORECASE): # FIXED: Made parentheses optional around the lifespan dates pattern = rf'\b{re.escape(composer)}\b\s*[()]?\s*\d{{4}}[-–—]\d{{4}}\s*[()]?' cleaned_piece = re.sub(pattern, '', safe_title, flags=re.IGNORECASE).strip() # If the above didn't catch it, clean just the standalone name token if cleaned_piece == safe_title.strip(): cleaned_piece = re.sub(rf'\b{re.escape(composer)}\b', '', safe_title, flags=re.IGNORECASE).strip() # Extra cleanup for lingering standalone lifespan blocks left in the title cleaned_piece = re.sub(r'\b\d{4}[-–—]\d{4}\b', '', cleaned_piece).strip() cleaned_piece = re.sub(r'^[,\-–—:;\s]+|[,\-–—:;\s]+$', '', cleaned_piece).strip() cleaned_piece = re.sub(r'\(\s*\)\s*$', '', cleaned_piece).strip() name_parts = composer.split() if len(name_parts) > 1: formatted_composer = f"{name_parts[-1]}, {' '.join(name_parts[:-1])}" else: formatted_composer = composer return formatted_composer, cleaned_piece # --- Fallback Logic --- nl_match = re.match(r'(?i)^Music of\s+(.*?)(?:\s+for\b|\s+performed by\b|\s+with\b|$)', safe_title) if nl_match: raw_composer = nl_match.group(1).strip() piece = video_title.strip() else: # FIXED: Also updated the fallback path date-stripper to handle optional parentheses date_pattern = r'[()]?\s*(?:b\.|c\.)?\s*\d{4}\s*[-–—]*\s*(?:\d{2,4})?\s*[()]?|\b\d{4}\s*[-–—]+\s*\d{2,4}\b|\b(?:b\.|c\.)\s*\d{4}\b' date_split = re.split(date_pattern, safe_title, maxsplit=1) if len(date_split) == 2 and date_split[1].strip(): raw_composer = date_split[0].strip() piece = date_split[1].strip() piece = re.sub(r'^[-–—:\s]+', '', piece) else: parts = re.split(r'\s+[-]\s+|[–—:]', safe_title, maxsplit=1) if len(parts) < 2: return "", video_title.strip() raw_composer = parts[0].strip() piece = parts[1].strip() word_count = len(raw_composer.split()) non_name_words = ['symphony', 'chorus', 'concert', 'festival', 'part', 'music', 'celebration', 'orchestra', 'beginnings', 'band', 'first', 'second', 'third', 'fourth', 'fifth', 'sixth', 'seventh', 'eighth', 'ninth', 'tenth', 'set', 'loss'] if word_count > 6 or any(w in raw_composer.lower() for w in non_name_words): return "", video_title.strip() raw_composer = re.sub(r'\(.*?\)', '', raw_composer) raw_composer = re.sub(r'\d+', '', raw_composer) raw_composer = re.sub(r'[:;,()~]', '', raw_composer) raw_composer = " ".join(raw_composer.split()) name_parts = raw_composer.split() if len(name_parts) <= 1: formatted_name = raw_composer else: last_name = name_parts[-1] first_names = " ".join(name_parts[:-1]) formatted_name = f"{last_name}, {first_names}" return formatted_name, piece def fetch_youtube_data(url, is_unlisted=False, cookie_file=None, playlist_range=None): js_executable = shutil.which("node") or shutil.which("nodejs") ydl_opts = { 'extract_flat': False, 'skip_download': True, 'quiet': False, 'verbose': False, 'ignoreerrors': True, 'socket_timeout': 5, 'retries': 3, 'fragment_retries': 3, 'sleep_interval': 2, 'max_sleep_interval': 10, 'extractor_args': {'youtube': {'client': ['android', 'ios']}}, 'js_runtimes': {'node': {'path': js_executable}}, } if cookie_file: ydl_opts['cookiefile'] = cookie_file if playlist_range: ydl_opts['playlist_items'] = playlist_range concert_data = [] with yt_dlp.YoutubeDL(ydl_opts) as ydl: try: info = ydl.extract_info(url, download=False) if not info: return [] videos = info.get('entries', [info]) for video in videos: if not video: continue video_title = video.get('title', 'Unknown Concert') if is_unlisted: video_link = "" else: video_link = f"https://www.youtube.com/watch?v={video.get('id')}" description = video.get('description', '') raw_date = video.get('upload_date', 'Unknown') formatted_date = raw_date if raw_date and raw_date.isdigit() and len(raw_date) == 8: formatted_date = datetime.strptime(raw_date, "%Y%m%d").strftime("%b %d, %Y") conductor = "Unknown" search_text = f"{video_title} \n {description}" for kc in KNOWN_CONDUCTORS: if re.search(rf'\b{re.escape(kc)}\b', search_text, re.IGNORECASE): conductor = kc break if conductor == "Unknown": cond_match = re.search(r'(?:Conductor:\s*|Conducted by\s*)([A-ZÀ-ÿ][a-zÀ-ÿ]+(?:\s+[A-ZÀ-ÿ][a-zÀ-ÿ]+){0,3})', search_text) if not cond_match: cond_match = re.search(r'([A-ZÀ-ÿ][a-zÀ-ÿ]+(?:\s+[A-ZÀ-ÿ][a-zÀ-ÿ]+){0,3})(?:,\s*Conductor|\s+-\s+Conductor|\s+conducts)', search_text) if cond_match: conductor = cond_match.group(1).strip() main_composer, main_piece = parse_classical_title(video_title) global_performer = "Unknown" for ensemble in sorted(KNOWN_ENSEMBLES, key=len, reverse=True): if re.search(rf'\b{re.escape(ensemble)}\b', search_text, re.IGNORECASE): global_performer = ensemble break if global_performer == "Unknown": perf_match = re.search(r'(?i)(?:performed by|with)\s+([^–—\-;:,(\n]+)', video_title) if perf_match: global_performer = perf_match.group(1).strip() elif re.search(r'(?i)\b(trio|quartet|quintet|ensemble|orchestra|chorus|band|winds|brass)\b', video_title) or (re.search(r'(?i)\bsymphony\b', video_title) and not re.search(r'(?i)\bsymphony\s+(no\.?|#|\d+)', video_title)): gp_split = re.split(r'(?i)[-–—:;,]|\b(?:at|in|plays|part|performs|presents)\b', video_title)[0].strip() gp_split = re.sub(r'(?i)^(ORCMA|Oak Ridge Civic Music Association)\s*(presents)?\s*', '', gp_split).strip() if len(gp_split.split()) <= 10: global_performer = gp_split tracks_found = 0 if description: lines = description.split('\n') for i, line in enumerate(lines): line = line.strip() if not line: continue if re.match(r'(?i)^\d{1,2}:\d{2}\s*[ap]\.?m\.?', line): continue clean_text = line is_track_line = False if re.match(r'^\d{1,2}:\d{2}(:\d{2})?\s*[-–—]*\s*', line): clean_text = re.sub(r'^\d{1,2}:\d{2}(:\d{2})?\s*[-–—]*\s*', '', line).strip() is_track_line = True else: for composer in KNOWN_COMPOSERS: if re.match(rf'^{re.escape(composer)}\s*[:\-–—;]\s+', line, re.IGNORECASE): is_track_line = True break if not is_track_line: continue date_pattern = r'\(\s*(?:b\.|c\.)?\s*\d{4}\s*[-–—]*\s*(?:\d{2,4})?\s*\)|\b\d{4}\s*[-–—]+\s*\d{2,4}\b|\b(?:b\.|c\.)\s*\d{4}\b' temp_no_dates = re.sub(date_pattern, '', clean_text) if not re.search(r'[-–—:]', temp_no_dates) and (i + 1 < len(lines)): next_line = lines[i+1].strip() if next_line and not re.match(r'^\d{1,2}:\d{2}', next_line): clean_text = clean_text + " - " + next_line junk_keywords = ['start', 'musicians', 'program notes', 'applause', 'intermission', 'tuning', 'concert', 'break'] if any(junk in clean_text.lower() for junk in junk_keywords): continue if is_movement(clean_text): continue composer, piece_and_soloist = parse_classical_title(clean_text) parts = re.split(r'\s+[-–—;]\s+', piece_and_soloist, maxsplit=1) if len(parts) == 2: piece = parts[0].strip() potential_soloist = parts[1].strip() # If the text after the hyphen is a tempo marking, do not treat it as a person tempos = r'(?i)\b(presto|allegro|andante|adagio|vivace|largo|moderato|rondo|gigue|finale)\b' if re.match(tempos, potential_soloist): piece = f"{piece} - {potential_soloist}" potential_soloist = "" if len(parts) == 2: piece = parts[0].strip() potential_soloist = parts[1].strip() is_conductor = False matched_kc = None for kc in KNOWN_CONDUCTORS: if kc.lower() in potential_soloist.lower(): is_conductor = True matched_kc = kc break if not is_conductor and "conductor" in potential_soloist.lower(): is_conductor = True if is_conductor: if matched_kc: leftover = re.sub(re.escape(matched_kc), '', potential_soloist, flags=re.IGNORECASE).strip() leftover = re.sub(r'(?i)\bconductor\b', '', leftover).strip() leftover = re.sub(r'^[,;\-\s]+|[,;\-\s]+$', '', leftover).strip() soloist = leftover if leftover else "Unknown" else: clean_str = re.sub(r'(?i)[,\-\s]*conductor[,\-\s]*', '', potential_soloist).strip() if len(clean_str.split()) <= 4: soloist = "Unknown" else: soloist = potential_soloist else: soloist = potential_soloist else: piece = piece_and_soloist.strip() soloist = "Unknown" if soloist == "Unknown" and global_performer != "Unknown": if not re.search(r'(?i)\b(orchestra|chorus|symphony|band)\b', global_performer): soloist = global_performer concert_data.append({ 'composer': composer, 'piece': piece, 'soloist': soloist, 'conductor': conductor, 'concert_title': video_title, 'link': video_link, 'date': formatted_date }) tracks_found += 1 if tracks_found == 0: fallback_soloist = global_performer if fallback_soloist == "Unknown": perf_match = re.search(r'(?i)performed by\s+(.*)', video_title) if perf_match: fallback_soloist = re.split(r'[-–—]', perf_match.group(1))[0].strip() # NEW: Catch festival name from the description if it's missing in the title final_concert_title = video_title if description and "Rock to Bach" in description: # Extract the specific year variant if it exists, e.g., "Rock to Bach 2020" festival_match = re.search(r'(?i)(Rock to Bach(?:\s+\d{4})?)', description) if festival_match: final_concert_title = festival_match.group(1).strip() concert_data.append({ 'composer': main_composer, 'piece': main_piece, 'soloist': fallback_soloist, 'conductor': conductor, 'concert_title': final_concert_title, 'link': video_link, 'date': formatted_date }) except Exception as e: print(f"An error occurred while connecting to YouTube: {e}") return [] return concert_data def update_archive(db_path, raw_concert_data): conn = sqlite3.connect(db_path) cursor = conn.cursor() cursor.execute(''' CREATE TABLE IF NOT EXISTS archive ( id INTEGER PRIMARY KEY AUTOINCREMENT, composer TEXT, piece TEXT, soloist TEXT, conductor TEXT, date TEXT, concert_title TEXT, link TEXT ) ''') cursor.execute("DELETE FROM archive") try: cursor.execute("DELETE FROM sqlite_sequence WHERE name='archive'") except sqlite3.OperationalError: pass seen_tracks = set() for entry in raw_concert_data: # Pull values, defaulting to a blank string if missing composer = entry.get('composer', '').strip() piece = entry.get('piece', '').strip() soloist = entry.get('soloist', '').strip() conductor = entry.get('conductor', '').strip() date = entry.get('date', '').strip() concert_title = entry.get('concert_title', '').strip() link = entry.get('link', '').strip() # Sanitize any explicit "Unknown" strings generated during earlier stages if composer == "Unknown": composer = "" if piece == "Unknown": piece = "" if soloist == "Unknown": soloist = "" if conductor == "Unknown": conductor = "" if date == "Unknown": date = "" if concert_title == "Unknown": concert_title = "" if "Rock to Bach" in concert_title or "Rock to Bach" in piece: composer = "Various Artists" if "—" in piece: parts = piece.split("—", 1) soloist = parts[1].strip() if len(parts) > 1 else parts[0].strip() piece = parts[0].strip() elif " - " in piece: parts = piece.split(" - ", 1) soloist = parts[1].strip() if len(parts) > 1 else parts[0].strip() piece = parts[0].strip() else: # NEW fallback: If there is no delimiter to split on, # the "piece" text is almost certainly the artist's name. if soloist == "Unknown" or soloist == "": soloist = piece piece = "Performance" # Or leave blank if preferred if piece == "Unknown" or piece == "": piece = concert_title track_signature = (composer, piece, soloist, conductor, concert_title) if track_signature in seen_tracks: continue seen_tracks.add(track_signature) cursor.execute(''' INSERT INTO archive (composer, piece, soloist, conductor, date, concert_title, link) VALUES (?, ?, ?, ?, ?, ?, ?) ''', (composer, piece, soloist, conductor, date, concert_title, link)) conn.commit() conn.close() print("Database successfully rebuilt and saved!") if __name__ == "__main__": my_db_file = "orcma_archive.db" rotator = CookieRotator( ['cookies_1.txt', 'cookies_3.txt', 'cookies_4.txt'], rotate_every=90 ) print("\n--- STAGE 1: Fetching Public Channel in Batches ---") youtube_playlist_url = "https://www.youtube.com/@orcma/videos" public_data = [] batch_size = 90 start_index = 1 while True: end_index = start_index + batch_size - 1 playlist_range = f"{start_index}-{end_index}" current_cookie = rotator.get_current() print(f"Scraping channel videos {playlist_range} using {current_cookie}...") batch = fetch_youtube_data( youtube_playlist_url, is_unlisted=False, cookie_file=current_cookie, playlist_range=playlist_range ) if not batch: break public_data.extend(batch) rotator.add_requests(len(batch)) if len(batch) < batch_size: break start_index += batch_size print(f"SUCCESS: Found {len(public_data)} public tracks.\n") if len(public_data) == 0: print("CRITICAL ERROR: Failed to fetch public videos.") print("All cookies may be blocked, or the connection dropped.") else: print("--- STAGE 2: Fetching Unlisted Archive ---") UNLISTED_VIDEOS = [ "https://youtu.be/example1", "https://youtu.be/example2" ] unlisted_data = [] for unlisted_url in UNLISTED_VIDEOS: current_cookie = rotator.get_current() tracks = fetch_youtube_data( unlisted_url, is_unlisted=True, cookie_file=current_cookie ) if tracks: unlisted_data.extend(tracks) rotator.add_requests(1) print(f"SUCCESS: Found {len(unlisted_data)} unlisted tracks.\n") print("--- STAGE 3: Rebuilding Database ---") all_data = public_data + unlisted_data update_archive(my_db_file, all_data)
And the code for the Web page display:
<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8"> <meta name="viewport" content="width=device-width, initial-scale=1.0"> <title>ORCMA Digital Archive</title> <link href="https://cdn.jsdelivr.net/npm/bootstrap@5.3.2/dist/css/bootstrap.min.css" rel="stylesheet"> <style> body { background-color: #f8f9fa; padding-top: 40px; } .table-hover tbody tr:hover { background-color: #f1f3f5; } </style> </head> <body> <div class="container-fluid px-5"> <h1 class="mb-4 text-center">ORCMA Digital Archive</h1> <p class="text-center text-muted mb-4">Database Last Updated: {{ last_updated }}</p> <div class="row justify-content-center mb-4"> <div class="col-md-6"> <form action="/" method="GET" class="d-flex"> <input type="text" name="q" class="form-control me-2" placeholder="Search composers, pieces, performers..." value="{{ search_query }}"> <button type="submit" class="btn btn-primary">Search</button> <a href="/" class="btn btn-outline-secondary ms-2">Clear</a> </form> </div> </div> <div class="card shadow-sm"> <div class="card-body p-0"> <div class="table-responsive"> <table class="table table-striped table-hover mb-0"> <thead class="table-dark"> <tr> <th>Composer</th> <th>Piece</th> <th>Performer</th> <th>Conductor</th> <th>Date</th> <th>Concert Title</th> <th>Link</th> </tr> </thead> <tbody> {% for row in performances %} <tr> <td class="fw-bold">{{ row['composer'] }}</td> <td>{{ row['piece'] }}</td> <td>{{ row['soloist'] if row['soloist'] else '<span class="text-muted">-</span>'|safe }}</td> <td>{{ row['conductor'] }}</td> <td>{{ row['date'] }}</td> <td class="small">{{ row['concert_title'] }}</td> <td> {% if row['link'] %} <a href="{{ row['link'] }}" target="_blank" class="btn btn-sm btn-danger">Watch</a> {% endif %} </td> </tr> {% else %} <tr> <td colspan="7" class="text-center py-4 text-muted">No performances found.</td> </tr> {% endfor %} </tbody> </table> </div> </div> </div> </div> </body> </html>
While it runs, it tells me what is happening:
. . . .
[download] Downloading item 37 of 90
[youtube] Extracting URL: https://www.youtube.com/watch?v=YHu05C7qN7Y
[youtube] YHu05C7qN7Y: Downloading webpage
[youtube] YHu05C7qN7Y: Downloading android vr player API JSON
[youtube] YHu05C7qN7Y: Downloading web embedded client config
[youtube] YHu05C7qN7Y: Downloading web embedded player API JSON
[youtube] [jsc:node] Solving JS challenges using node
[youtube] YHu05C7qN7Y: Downloading m3u8 information
[download] Downloading item 38 of 90
[youtube] Extracting URL: https://www.youtube.com/watch?v=o6dRlkFJyCk
[youtube] o6dRlkFJyCk: Downloading webpage
[youtube] o6dRlkFJyCk: Downloading android vr player API JSON
[youtube] o6dRlkFJyCk: Downloading web embedded client config
[youtube] o6dRlkFJyCk: Downloading web embedded player API JSON
[youtube] [jsc:node] Solving JS challenges using node
[youtube] o6dRlkFJyCk: Downloading m3u8 information
[download] Downloading item 39 of 90
[youtube] Extracting URL: https://www.youtube.com/watch?v=Jmdx8W8LgKM
[youtube] Jmdx8W8LgKM: Downloading webpage
[youtube] Jmdx8W8LgKM: Downloading android vr player API JSON
[youtube] [jsc:node] Solving JS challenges using node
[youtube] Jmdx8W8LgKM: Downloading m3u8 information
[download] Downloading item 40 of 90
. . . .
Remembering Gemini context
A big problem with Gemini is that as of now, it does not remember its context. It loses context when you accidentally close the chat, switch devices, or install a Gemini update. But you can save it manually, although Gemini and I made many failed attempts at this:
Based on our chat history, after several attempts with built-in tools, browser settings, and extensions, the most reliable way to export your full chat context was a manual "brute-force" copy and paste into a Google Doc.
Here is a summary of why the standard features failed, and the successful method you ultimately used:
Why the built-in methods failed:
-
The Export Buttons: The standard "Export to Google Docs" and "Draft in Gmail" buttons are "single-turn" tools that only capture the one specific message directly above the button, ignoring the rest of your chat history
. -
Printing to PDF: Attempting to print the shared public link to a PDF only yielded one page because the browser print engine gets fooled by the dynamic web application container
. -
Reader Mode: Forcing the browser into Reader Mode to fix the PDF pagination backfired because it treated the code blocks like headers, completely destroying the spacing and blowing up the font size
. -
The Copy Button: The UI's built-in clipboard button struggles with the sheer size of massive scripts and intermittently fails to capture the full text of a long response
. -
GoFullPage Extension: Even using a highly-rated Chrome extension to take a scrolling PDF screenshot resulted in mangled code
.
The Successful Extraction Method: To successfully capture the entire chat context and easily read your notes without ruining the layout, you bypassed the UI entirely using this plain-text method:
-
Click anywhere on the blank space inside the chat window
. -
Press
Cmd + A(Mac) orCtrl + A(Windows) to highlight the entire page. -
Press
Cmd + C/Ctrl + Cto copy the text. -
Open your Google Doc and press
Cmd + Shift + V/Ctrl + Shift + Vto paste it as plain text.
Pasting the text as plain text was the critical final step. It stripped out the hidden web containers and background CSS, forcing Google Docs to accept the text cleanly and preventing the formatting from blowing up into giant fonts
Similarly, to extract the massive, fully formatted Python script without the UI cutting it off, you clicked inside the code box, used Cmd + A to highlight everything inside, and manually copied it to paste into your update_archive.py file
🌐 The Tor Proxy Saga (An Abandoned Alternative)
During our initial staging runs on jarfx, the scraper hit a hard wall after exactly 187 queries, triggering an aggressive HTTP 429 Too Many Requests rate-limit block from YouTube. To bypass an outright IP ban, our first architectural instinct was to mask the server's identity by routing yt-dlp traffic through a local Tor SOCKS5 proxy. We injected this option directly into the ydl_opts configuration dictionary:
'proxy': 'socks5://127.0.0.1:9050'
How the Tor Workaround Functioned
-
IP Masking: Tunneling requests through Tor completely masked the server's real static IP address behind a rotating global exit node.
-
Instant Identity Swaps: If a specific exit node got flagged or throttled by YouTube, we didn't have to wait it out. We could jump into the server terminal and force a brand-new digital identity instantly by restarting the daemon:
sudo systemctl restart tor.
🛑 Why We Omitted It From the Final Production Code
While it served as a great technical insurance policy, we ultimately stripped the proxy settings out of the final version of the script for two major reasons:
-
The Severe Speed Penalty: Tor encrypts and bounces your traffic across three separate international relays before it ever hits its destination. For a script trying to parse hundreds of detailed video descriptions sequentially, this immense network overhead caused connection response times to crawl.
-
The Elegance of Cookie Rotation: Once we re-engineered the script to use your custom
CookieRotatorclass—chunking the public channel requests into tight batches of 90 and systematically cycling through your four unique browser cookie files—YouTube's automated security stopped treating the traffic as a malicious bot.
By pairing multi-cookie rotation with a randomized, human-like delay ('sleep_interval': 5), the script successfully flew under the radar over our standard server connection.
Add new comment